awk 命令详解
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z

awk 命令安装:
-bash/zsh: awk command not found #Debian apt-get install gawk #Ubuntu apt-get install gawk #Alpine apk add gawk #Arch Linux pacman -S gawk #Kali Linux apt-get install gawk #CentOS yum install gawk #Fedora dnf install gawk #OS X brew install awk #Raspbian apt-get install gawk #Docker docker run cmd.cat/awk awk
awk 命令说明:

awk 命令补充说明:
AWK 是另一种流行的流编辑器,类似于 SED。 awk 的基本功能是在文件中搜索包含一种或多种模式的行或其他文本单元。 当一行与其中一个模式匹配时,会对该行执行特殊操作。
有几种方法可以运行 awk。 如果程序很短,最简单的方法是在命令行上运行它:
awk PROGRAM inputfile(s)
如果必须对多个文件进行多次更改,可能定期对多个文件进行更改,则将 awk 命令放在脚本中会更容易。 这是这样读的:
awk -f PROGRAM-FILE inputfile(s)
awk 中最常用的程序是 print,我们很快就会看到。awk 中的打印命令从输入文件中输出选定的数据。变量 $1, $2, $3, ..., $N 保存输入行的第一个、第二个、第三个直到最后一个字段的值。 变量 $0(零)保存整行的值。
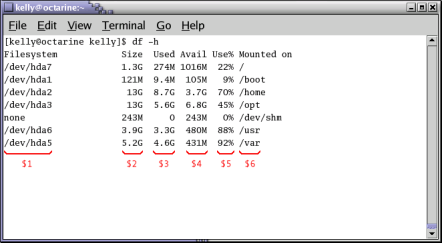
如上图:要打印大小 $2 和使用% $5,请使用 df -h | awk '{print $2,$5}' ,注意:$2,$5:它们之间的 , 将用 空格 分隔输出。
$ df -h | awk '{print $2,$5}'
-------------------
Size Use%
40G 25%
7.8G 0%
7.8G 0%
7.8G 1%
7.8G 0%
1000G 12%
1.6G 0%
1.6G 0%
awk 命令语法:
awk [-F sepstring] [-v assignment]... program [argument...] awk [-F sepstring] -f progfile [-f progfile]... [-v assignment]...[argument...]
awk 命令选项:
-F sepstring
Define the input field separator. This option shall be
equivalent to:
-v FS=sepstring
except that if -F sepstring and -v FS=sepstring are
both used, it is unspecified whether the FS assignment
resulting from -F sepstring is processed in command
line order or is processed after the last -v
FS=sepstring. See the description of the FS built-in
variable, and how it is used, in the EXTENDED
DESCRIPTION section.
-f progfile
Specify the pathname of the file progfile containing an
awk program. A pathname of '-' shall denote the
standard input. If multiple instances of this option
are specified, the concatenation of the files specified
as progfile in the order specified shall be the awk
program. The awk program can alternatively be specified
in the command line as a single argument.
-v assignment
The application shall ensure that the assignment
argument is in the same form as an assignment operand.
The specified variable assignment shall occur prior to
executing the awk program, including the actions
associated with BEGIN patterns (if any). Multiple
occurrences of this option can be specified.
awk 命令实例:
awk 在空格分隔的文件中打印第五列(又名字段):
awk '{print $5}' filename
awk 在空格分隔的文件中打印包含“某物”的行的第二列:
awk '/something/ {print $2}' filename
awk 打印文件中每一行的最后一列,使用逗号(而不是空格)作为字段分隔符:
awk -F ',' '{print $NF}' filename
awk 对文件第一列中的值求和并打印总数:
awk '{s+=$1} END {print s}' filename
awk 对第一列中的值求和并漂亮地打印这些值,然后是总数:
awk '{s+=$1; print $1} END {print "--------"; print s}' filename
awk 从第一行开始每三行打印一次:
awk 'NR%3==1' filename
awk Formatting 格式化字段输出:
$ df -h | sort -rnk 5 | head -3 | awk '{ print "Partition " $6 "\t: " $5 " full!" }'
Partition /mnt/sdb6 : 99% full!
Partition /mnt/sdb5 : 97% full!
Partition /home : 89% full!
awk / gawk 字符串格式化:
| Sequence | 含义 |
|---|---|
| \a | Bell character |
| \n | Newline character |
| \t | Tab |
awk 打印命令和正则表达式,例如,从 /etc 目录列出以字母 a 或 c 开头并以 .conf 结尾的文件并打印第 9 个字段:
$ ls -l /etc/ | awk '/\<(a|c).*\.conf$/ { print $9 }'
adduser.conf
apg.conf
ca-certificates.conf
casper.conf
resolv.conf
awk 脚本方式,我们使用 BEGIN、END,正则表达式配置到 test.awk 中,然后运行:
BEGIN { print "*** WARNING WARNING WARNING ***" }
/\<[8|9][0-9]%/ { print "Partition " $6 "\t: " $5 " full!" }
END { print "*** Give money for new disks URGENTLY! ***" }
$ df -h | awk -f test.awk
*** WARNING WARNING WARNING ***
Partition / : 89% full!
Partition /mnt/sdb5 : 97% full!
Partition /mnt/sdb6 : 99% full!
Partition /home : 89% full!
*** Give money for new disks URGENTLY! ***
awk 的 RS、ORS 与 FS、OFS 及 NR、NF:
RS:Record Separator,记录分隔符 ORS:Output Record Separate,输出当前记录分隔符 FS:Field Separator,字段分隔符 OFS:Out of Field Separator,输出字段分隔符 NR:Number of Records 当前行数 NF:Number of Fields 字段数量
假设 test.txt 文件有 100 行,awk 只取第 20 到第 30 行内容:
awk '{if(NR>=20 && NR<=30) print $1}' test.txt
awk 扩展阅读:
- Linux awk command
- Uso del comando AWK en Linux y UNIX con ejemplos - 通过示例在 Linux 和 UNIX 上使用 AWK 命令
- Gawk
- Linux 删除乱码怪异字符的目录,rm 怪异文件名
- vim 命令详解
- nvim 命令详解
- sort 命令详解
- egrep 命令
- pgrep 命令
- bzgrep 命令
- cut 命令
- jq 命令
- tokei 命令
- protoc 命令
- grep 命令
- awk 命令
- sed 命令
CommandNotFound ⚡️ 坑否 - 其他频道扩展阅读:
awk 命令评论
-
7zr 命令
aapt 命令
ack 命令
ar 命令
arj 命令
awk 命令
base32 命令
base64 命令
basename 命令
blkid 命令
blockdev 命令
bunzip2 命令
bzcat 命令
bzcmp 命令
bzdiff 命令
bzgrep 命令
bzip2 命令
bzip2recover 命令
bzless 命令
bzmore 命令
chattr 命令
chcon 命令
cksum 命令
cmp 命令
col 命令
colrm 命令
comm 命令
compress 命令
cp 命令
csplit 命令
csvstat 命令
cut 命令
dd 命令
diff 命令
diff3 命令
dircolors 命令
dirname 命令
dirs 命令
dump 命令
ed 命令
edit 命令
egrep 命令
enca 命令
ex 命令
extundelete 命令
file 命令
fmt 命令
fold 命令
fsck 命令
getfattr 命令
gettext 命令
grep 命令
gron 命令
gzip 命令
head 命令
join 命令
jq 命令
less 命令
link 命令
ln 命令
ls 命令
lsattr 命令
md5sum 命令
mkdir 命令
mmv 命令
more 命令
most 命令
msgfmt 命令
msginit 命令
mv 命令
namei 命令
nano 命令
nl 命令
nvim 命令
od 命令
paste 命令
pax 命令
rdfind 命令
rename 命令
rm 命令
rmdir 命令
sed 命令
setfattr 命令
sha224sum 命令
sha256sum 命令
sha384sum 命令
sha512sum 命令
shred 命令
sort 命令
srm 命令
stat 命令
strings 命令
sum 命令
tail 命令
tailf 命令
tar 命令
tee 命令
touch 命令
tr 命令
trash 命令
unarj 命令
uniq 命令
unlink 命令
unzip 命令
vi 命令
view 命令
vim 命令
vsftpd 命令
wc 命令
xargs 命令
xgettext 命令
zcat 命令
zip 命令
zipinfo 命令
zipsplit 命令
znew 命令
zstd 命令