sed 命令详解
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
sed 命令安装:
-bash/zsh: sed: command not found #Windows (WSL2) sudo apt-get update sudo apt-get install sed #Debian apt-get install sed #Ubuntu apt-get install sed #Alpine apk add sed #Arch Linux pacman -S sed #Kali Linux apt-get install sed #CentOS yum install sed #Fedora dnf install sed #Raspbian apt-get install sed #Dockerfile dockerfile.run/sed #Docker docker run cmd.cat/sed sed
sed 命令补充说明:
sed 是流编辑器。 流编辑器用于对输入流(文件或管道输入)执行基本的文本转换。 尽管在某种程度上类似于允许脚本编辑(例如 ed)的编辑器,但 sed 通过仅对输入进行一次传递来工作,因此效率更高。 但是 sed 能够过滤管道中的文本,这使其与其他类型的编辑器特别有区别。
sed 处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间” pattern space,接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有被改变,除非你使用重定向存储输出。sed 主要用来自动编辑一个或多个文件:简化对文件的反复操作、编写转换程序等。
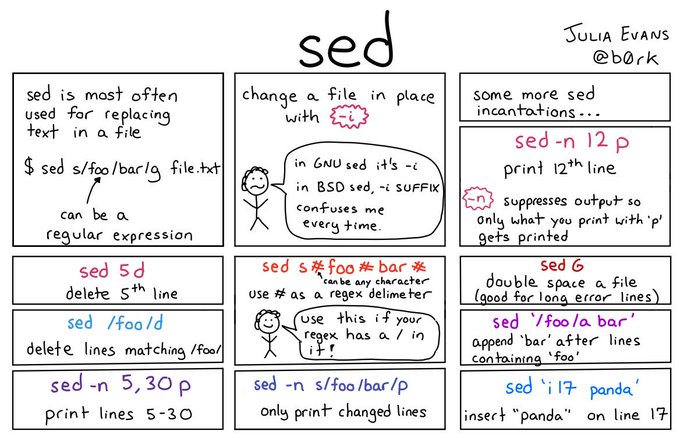
sed 命令语法:
sed OPTIONS... [SCRIPT] [INPUTFILE...] #如果未指定INPUTFILE或INPUTFILE为“-”,则sed过滤标准输入的内容。 #该脚本实际上是第一个非选项参数,当且仅当其他选项均未指定要执行的脚本(即-e和-f均未指定)时,sed才会特别考虑该脚本而不是输入文件选。项
sed 命令选项:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。 -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。 -h或--help 显示帮助。 -n或--quiet或--silent 仅显示script处理后的结果。 -V或--version 显示版本信息。
sed 命令动作说明:
a\ # 在当前行下面插入文本。 i\ # 在当前行上面插入文本。 c\ # 把选定的行改为新的文本。 d # 删除,删除选择的行。 D # 删除模板块的第一行。 s # 替换指定字符 h # 拷贝模板块的内容到内存中的缓冲区。 H # 追加模板块的内容到内存中的缓冲区。 g # 获得内存缓冲区的内容,并替代当前模板块中的文本。 G # 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l # 列表不能打印字符的清单。 n # 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N # 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p # 打印模板块的行。 P # (大写) 打印模板块的第一行。 q # 退出Sed。 b lable # 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 r file # 从file中读行。 t label # if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label # 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file # 写并追加模板块到file末尾。 W file # 写并追加模板块的第一行到file末尾。 ! # 表示后面的命令对所有没有被选定的行发生作用。 = # 打印当前行号码。 # # 把注释扩展到下一个换行符以前。
sed 替换标记:
g # 表示行内全面替换。 p # 表示打印行。 w # 表示把行写入一个文件。 x # 表示互换模板块中的文本和缓冲区中的文本。 y # 表示把一个字符翻译为另外的字符(但是不用于正则表达式) \1 # 子串匹配标记 & # 已匹配字符串标记
sed 元字符集:
^ # 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ # 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. # 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
* # 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] # 匹配一个指定范围内的字符,如/[ss]ed/匹配sed和Sed。
[^] # 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\) # 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
& # 保存搜索字符用来替换其他字符,如s/love/ **&** /,love这成 **love** 。
\< # 匹配单词的开始,如:/\<love/匹配包含以love开头的单词的行。
\> # 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} # 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。
x\{m,\} # 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。
x\{m,n\} # 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。
sed 命令参数:
文件:指定待处理的文本文件列表。
sed 命令实例
sed 替换操作:s 命令
#替换文本中的字符串: sed 's/book/books/' file #-n选项 和 p命令 一起使用表示只打印那些发生替换的行: sed -n 's/test/TEST/p' file #直接编辑文件 选项-i ,会匹配file文件中每一行的所有book替换为books: sed -i 's/book/books/g' file
sed 全面替换标记 g
#使用后缀 /g 标记会替换每一行中的所有匹配: sed 's/book/books/g' file #当需要从第N处匹配开始替换时,可以使用 /Ng: echo sksksksksksk | sed 's/sk/SK/2g' skSKSKSKSKSK echo sksksksksksk | sed 's/sk/SK/3g' skskSKSKSKSK echo sksksksksksk | sed 's/sk/SK/4g' skskskSKSKSK
sed 定界符
以上命令中字符 / 在 sed 中作为定界符使用,也可以使用任意的定界符:
sed 's:test:TEXT:g' sed 's|test|TEXT|g' #定界符出现在样式内部时,需要进行转义: sed 's/\/bin/\/usr\/local\/bin/g'
删除操作:d 命令
#删除空白行: sed '/^$/d' file #删除文件的第2行: sed '2d' file #删除文件的第2行到末尾所有行: sed '2,$d' file #删除文件最后一行: sed '$d' file #删除文件中所有开头是test的行: sed '/^test/'d file
sed 已匹配字符串标记 &
正则表达式 \w+ 匹配每一个单词,使用 [&] 替换它,& 对应于之前所匹配到的单词:
echo this is a test line | sed 's/\w\+/[&]/g' [this] [is] [a] [test] [line] 所有以 192.168.0.1 开头的行都会被替换成它自已加 localhost: sed 's/^192.168.0.1/&localhost/' file 192.168.0.1localhost
sed 子串匹配标记 \1,匹配给定样式的其中一部分:
#下面命令中 digit 7,被替换成了 7。样式匹配到的子串是 7 echo this is digit 7 in a number | sed 's/digit \([0-9]\)/\1/' this is 7 in a number #(..) 用于匹配子串,对于匹配到的第一个子串就标记为 \1 ,依此类推匹配到的第二个结果就是 \2 ,例如: echo aaa BBB | sed 's/\([a-z]\+\) \([A-Z]\+\)/\2 \1/' BBB aaa #love被标记为1,所有loveable会被替换成lovers,并打印出来: sed -n 's/\(love\)able/\1rs/p' file
sed 组合多个表达式
sed '表达式' | sed '表达式' #等价于: sed '表达式; 表达式'
sed 引用
sed 表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号。
test=hello echo hello WORLD | sed "s/$test/HELLO" HELLO WORLD
sed 选定行的范围:,(逗号)
#所有在模板 test 和 check 所确定的范围内的行都被打印: sed -n '/test/,/check/p' file #打印从第5行开始到第一个包含以test开始的行之间的所有行: sed -n '5,/^test/p' file #对于模板 test 和 west 之间的行,每行的末尾用字符串aaa bbb替换: sed '/test/,/west/s/$/aaa bbb/' file
sed 多点编辑:e 命令
-e 选项允许在同一行里执行多条命令: sed -e '1,5d' -e 's/test/check/' file #上面sed表达式的第一条命令删除1至5行, #第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。 #和 -e 等价的命令是 --expression: sed --expression='s/test/check/' --expression='/love/d' file
sed 从文件读入:r 命令
#file 里的内容被读进来,显示在与 test 匹配的行后面,如果匹配多行,则 file 的内容将显示在所有匹配行的下面: sed '/test/r file' filename
sed 写入文件:w 命令
#在example中所有包含test的行都被写入file里: sed -n '/test/w file' example
sed 追加(行下):a\ 命令
#将 this is a test line 追加到 以test 开头的行后面: sed '/^test/a\this is a test line' file #在 test.conf 文件第2行之后插入 this is a test line: sed -i '2a\this is a test line' test.conf
sed 插入(行上):i\ 命令
#将 this is a test line 追加到以test开头的行前面: sed '/^test/i\this is a test line' file #在test.conf文件第5行之前插入this is a test line: sed -i '5i\this is a test line' test.conf
sed 下一个:n 命令
如果 test 被匹配,则移动到匹配行的下一行,替换这一行的 aa,变为 bb,并打印该行,然后继续:
sed '/test/{ n; s/aa/bb/; }' file
sed 变形:y 命令
把 1~10 行内所有 abcde 转变为大写,注意:正则表达式元字符不能使用这个命令:
sed '1,10y/abcde/ABCDE/' file
退出:q 命令
#打印完 10 行后,退出 sed sed '10q' file
sed 保持和获取:h 命令和 G 命令
#在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中, #除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。 sed -e '/test/h' -e '$G' file #在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。 #第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。 #在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h 命令和 x 命令
#互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换: sed -e '/test/h' -e '/check/x' file
sed 脚本 scriptfile
sed 脚本是一个 sed 的命令清单,启动 sed 时以 -f 选项引导脚本文件名。sed 对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。
以 # 开头的行为注释行,且不能跨行。
sed [options] -f scriptfile file(s)
打印奇数行或偶数行、打印匹配字符串的下一行
#方法1:
sed -n 'p;n' test.txt #奇数行
sed -n 'n;p' test.txt #偶数行
#方法2:
sed -n '1~2p' test.txt #奇数行
sed -n '2~2p' test.txt #偶数行
grep -A 1 SCC URFILE
sed -n '/SCC/{n;p}' URFILE
awk '/SCC/{getline; print}' URFILE
将文件 myfile.txt 的内容加双倍空格,并将输出写入文件 newfile.txt。
sed G myfile.txt > newfile.txt
计算 myfile.txt 中的行数并显示结果。
sed -n '$=' myfile.txt
sed 替换内容中有斜杠该怎么处理:
为了提高可读性,分隔符可由 / 换成 #(其他字符也可以,需跟在 s 命令后面即可):
sed -i 's#/a/b/c#/d/e/f#g'
sed 命令扩展阅读:
- Linux sed command
- jq 命令
- tokei 命令
- protoc 命令
- grep 命令
- awk 命令
- sed 命令
- cut 命令详解
- ed 命令
- vi 命令
- vim 命令
- vigr 命令
- vipw 命令
- edit 命令
CommandNotFound ⚡️ 坑否 - 其他频道扩展阅读:
sed 命令评论
-
7zr 命令
aapt 命令
ack 命令
ar 命令
arj 命令
awk 命令
base32 命令
base64 命令
basename 命令
blkid 命令
blockdev 命令
bunzip2 命令
bzcat 命令
bzcmp 命令
bzdiff 命令
bzgrep 命令
bzip2 命令
bzip2recover 命令
bzless 命令
bzmore 命令
chattr 命令
chcon 命令
cksum 命令
cmp 命令
col 命令
colrm 命令
comm 命令
compress 命令
cp 命令
csplit 命令
csvstat 命令
cut 命令
dd 命令
diff 命令
diff3 命令
dircolors 命令
dirname 命令
dirs 命令
dump 命令
ed 命令
edit 命令
egrep 命令
enca 命令
ex 命令
extundelete 命令
file 命令
fmt 命令
fold 命令
fsck 命令
getfattr 命令
gettext 命令
grep 命令
gron 命令
gzip 命令
head 命令
join 命令
jq 命令
less 命令
link 命令
ln 命令
ls 命令
lsattr 命令
md5sum 命令
mkdir 命令
mmv 命令
more 命令
most 命令
msgfmt 命令
msginit 命令
mv 命令
namei 命令
nano 命令
nl 命令
nvim 命令
od 命令
paste 命令
pax 命令
rdfind 命令
rename 命令
rm 命令
rmdir 命令
sed 命令
setfattr 命令
sha224sum 命令
sha256sum 命令
sha384sum 命令
sha512sum 命令
shred 命令
sort 命令
srm 命令
stat 命令
strings 命令
sum 命令
tail 命令
tailf 命令
tar 命令
tee 命令
touch 命令
tr 命令
trash 命令
unarj 命令
uniq 命令
unlink 命令
unzip 命令
vi 命令
view 命令
vim 命令
vsftpd 命令
wc 命令
xargs 命令
xgettext 命令
zcat 命令
zip 命令
zipinfo 命令
zipsplit 命令
znew 命令
zstd 命令