云平台 Linux 服务器问题场景分析思路及工具箱详解
|
选择喜欢的代码风格
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Linux 服务器 CPU、I/O、内存性能异常的常用工具、判定标准、以及分析思路。
Linux 服务器异常宕机的故障可能的原因、定位方法与常规分析思路。
Linux 服务器丢包的问题可能的原因、定位方法与常规分析思路。
Linux 服务器异常宕机的故障可能的原因、定位方法与常规分析思路。
Linux 服务器丢包的问题可能的原因、定位方法与常规分析思路。
Linux 服务器 CPU、I/O、内存性能异常
CPU 异常
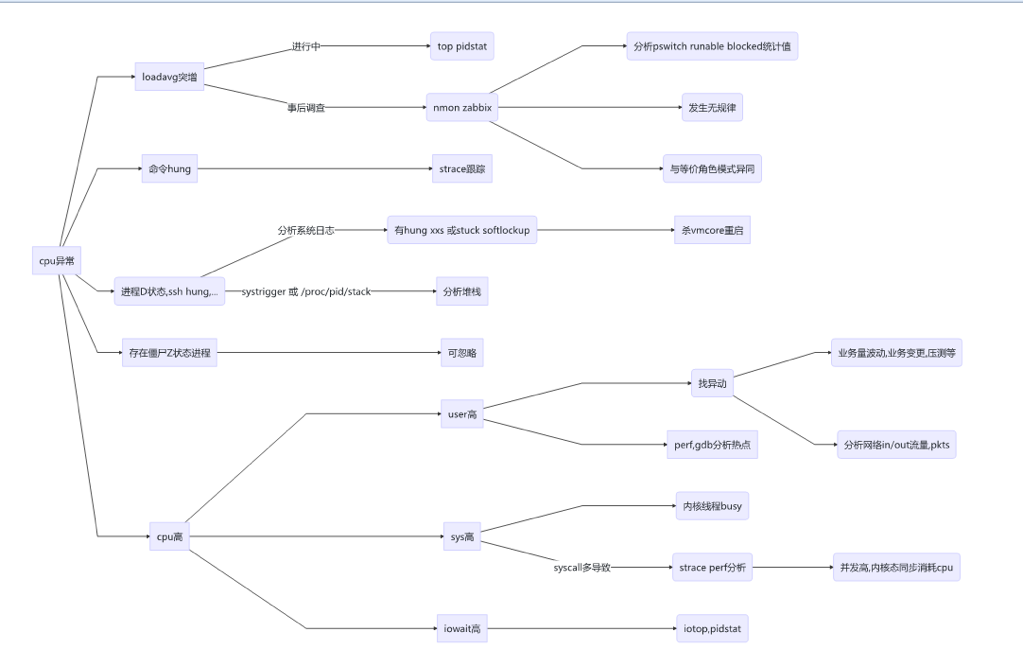 图 1 CPU 异常分解
图 1 CPU 异常分解
top
top -H -d 1 -c 高亮列及运行进程 z x y 选择 shift+L/Rarrow
pidstat
• -d 磁盘读写报告 I/O 统计 • -r 内存使用及缺页 • -u CPU • -l 展示命令行及参数 • -w switch • -t 显示线程的统计 • -T 每秒展示活动进程的 CPU 使用率 pidstat -u 1 按线程组关系聚合展示 CPU 消耗时间,帮助找出 busy 线程 pidstat -t 1 -T ALL
sar
• -b 块统计 • -B 页面 • -r 页面使用统计 • -R 页面回收统计 • -d 磁盘使用统计 • -q 调度统计 • -S swap • -m 运行频率 • -v 文件 inode dentry 活动统计 • -w 调度 switch • -W 换入换出统计 • -n 网络 DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6 and UDP6 • -s 00:00:00 -e 00:21:00 指明要查看的开始结束时间
iotop
iostat
strace
• -c 统计系统调用次数及时间 • -f 也 trace 子进程调用 • -e 指明关心的调用 eg. -e open,write 命令执行时挂起,了解进程挂在哪个 syscall strace cmd arg 进程系统调用开销较大,获取 syscall 统计 strace -p PID -c
gdb
• bt 查看执行堆栈 • frame 切换工作帧 用户进程的 cpu 消耗影响系统整体使用,配合 debuginfo 及代码可大致梳理出占用逻辑,attach 后,进程会 STOP gdb -p PID
perf
perf top 在线采样及展示: • -e 指明事件,默认是 cycle,全部时间可 perf list 查询 • -G 调用图 • -F 采样频率 • -d 刷新间隔 • -p 特定进程 • -C 特定核 perf top -d1 -G -F 99 -z shift + e 可展开堆栈视图 shift + c 可折叠堆栈视图
perf record/report
- record 输出采样文件 perf.data 文件
- report 解析
perf record -F 99 -a -g -p PID -C 6 sleep 5 perf report
内存异常
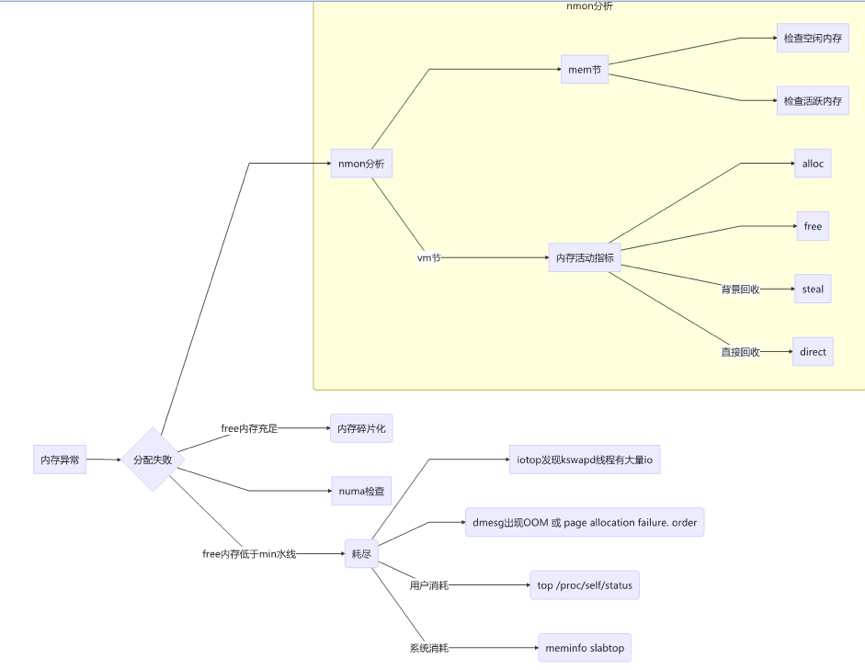 图 2 内存异常分解
图 2 内存异常分解
一般检查
free
free cat /proc/self/status cat /proc/self/smaps numastat -m numactl --hardware cat /proc/meminfo
zoneinfo
[root@TestMaster ~]
$ cat /proc/zoneinfo |egrep "zone|min|low|high|free|present"
Node 0, zone DMA
pages free 3977
min 33
low 41
high 49
present 3998
nr_free_pages 3977
nr_free_cma 0
high: 0
high: 0
high: 0
high: 0
Node 0, zone DMA32
pages free 27743
min 6117
low 7646
high 9175
present 782298
nr_free_pages 27743
nr_free_cma 0
high: 186
high: 186
high: 186
high: 186
Node 0, zone Normal
pages free 29987
min 10744
low 13430
high 16116
present 1310720
nr_free_pages 29987
nr_free_cma 0
high: 186
high: 186
high: 186
high: 186
三条水线
sysctl -a|grep extra_free_kbytes min_free_kbytes extra_free_kbytes 的组合值构成三个水线。
• 直接回收线 MIN min_free_kbytes • 后台回收线 LOW 5/4*min_free_kbytes + extra_free_kbytes • 后台回收停止 HIGH 3/2 * min_free_kbytes + extra_free_kbytes
内核结构缓冲
slabtop 了解当前内核数据结构内存消耗
I/O 异常
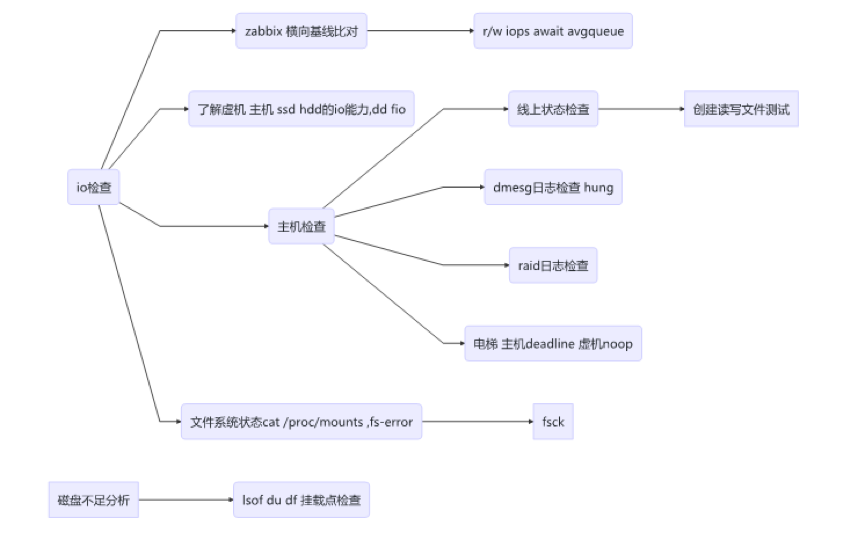 图 3 I/O 异常分解
图 3 I/O 异常分解
io scheduler
cfq deadline noop
blktrace & blkparser
当意外的 I/O 延迟发生,需要深入了解 I/O 延迟分布,需要使用 blktrace & blkparser 工具进行细致分析。
dd
学会合理使用 oflag 标志 sync 同步刷出数据 direct 绕过 pagecache。
fio
#用来标定系统 I/O 能力的便捷工具: fio -filename=/dev/mapper/vg_os-testlv -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=8k -size=100G -numjobs=96 -runtime=60 -group_reporting -name=mytest
du、df
面向块占用及文件系统占用的查询分析:
strace 可以看出两个命令原理的差异:df 读取文件系统信息,du stat 各个文件然后累加。
两者出入较大需进一步考察: 是否存在空洞? 是否一个文件用户已经看不到但是文件系统还没有真正删除?(就是打开文件被删除的情况 lsof +L1) 是否被某些挂载点隐藏了之前的目录文件? df 显示错误的话怀疑是否 fs 损坏?
网络异常场景
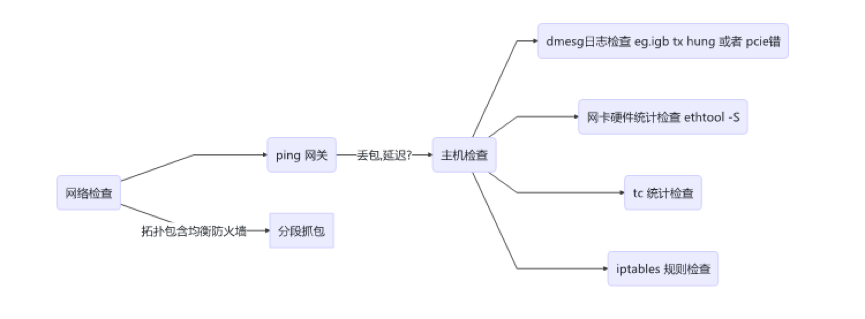 图 4 网络异常分析
图 4 网络异常分析
ethtool
ethtool -S 关注 drop error
tc -s -d qd 关注包 drop 情况
ss、netstat、iftop、dstat
常用连接查看 netstat -ntp netstat -ntpl ss -ie ss -s dstat 3 10
tcpdump
• -i 待抓取的网口名字 • -w 抓包文件,可以是时间格式化串 • -G 回滚时长,单位秒 • -c 抓取多少个包后退出 • -s 抓取部分报文,单位字节 • -r 读取抓包文件离线分析 • -z 调用 gzip 等工具做压缩 • -Z 切换 user 运行,默认是 tcpdump • -B 设置 buf 大小,不然抓不全单位 KB 10240 tcpdump tcp port 80 and host tcpdump -s0 -w %m_%d_%H_%M_%S.pcap -G 5 -z gzip -Z root -c 100000 -i any
宕机场景分析
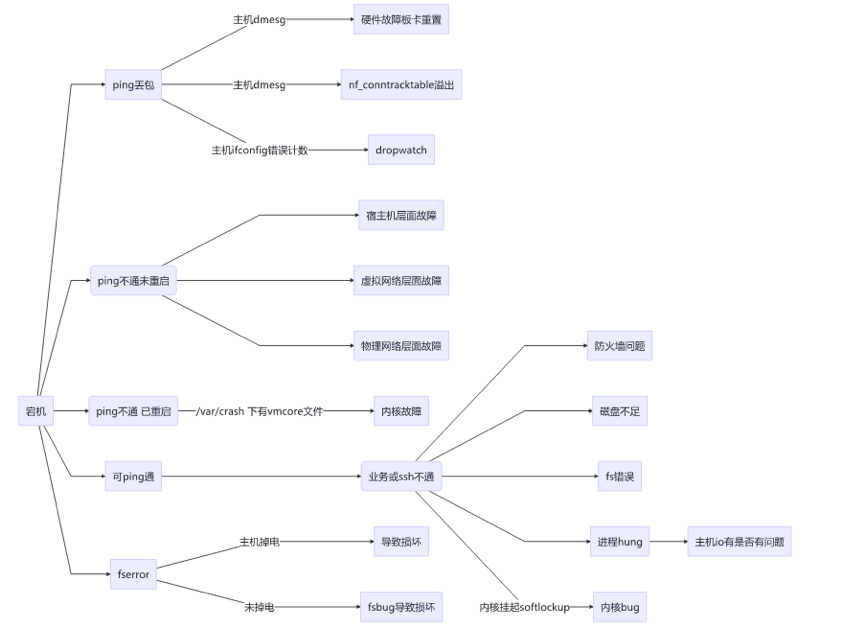 图 4 网络异常分析
图 4 网络异常分析
dropwatch crash 工具
• log 查看宕机关联日志 • bt 查看宕机位置 • sys 查看基本信息 crash vmcore vmlinux vmlinux 来自于 kernel debuginfo 包,是带调试信息的二进制内核镜像 如果系统未正确生成 vmcore, 需检查 /etc/kdump.conf 配置及其中的设定 vmcore 路径 此处讨论已开始涉及内核态问题,常见异常分析领域不再展开
服务器问题扩展阅读:
- 在 Linux 中如何使用 iotop 和 iostat 监控磁盘 I/O 活动?
- 谢英豪 - 云平台 Linux 服务器问题场景分析思路及工具箱
- tc 命令详解
- pidstat 命令
- iostat 命令
- dstat 命令
- vmstat 命令
- mpstat 命令
- dstat 命令
- nload 命令
CommandNotFound ⚡️ 坑否 - 其他频道扩展阅读:
云平台 Linux 服务器问题场景分析思路及工具箱评论
奇淫巧技
-
Linux TCP 状态 TIME_WAIT 过多的处理
No space left on device:Inode 已耗尽
云平台 Linux 服务器问题场景分析思路及工具箱
ngx_waf 安装避坑
MS-DOS vs. Linux 和 Unix
云服务器 SSH 连接一段时间就断掉的解决办法
Git 的 CRLF,LF 问题
用 Bash 脚本监控 Linux 上的内存使用情况
Linux 查看硬盘信息方法总结
vim 列编辑模式总结
Web 状态码检测监控提醒
Antigen
命令行录制工具 asciinema
certbot 命令
certbot-auto 命令
dash 命令
dive 命令
fish 命令
hr 命令
hugo 命令
jhat 命令
ksh 命令
oh-my-zsh
opencc 命令
progress 命令
screen 命令
wine 命令
xeyes 命令
xxd 命令
zsh 工具
共收录到 549 个 Linux 命令