sort 命令详解
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
sort 命令安装:
-bash/zsh: sort command not found #Debian apt-get install coreutils #Ubuntu apt-get install coreutils #Alpine apk add coreutils #Arch Linux pacman -S coreutils #Kali Linux apt-get install coreutils #CentOS yum install coreutils #Fedora dnf install coreutils #OS X brew install coreutils #Raspbian apt-get install coreutils #Docker docker run cmd.cat/sort sort
sort 命令补充说明:
sort 是一个简单且非常有用的命令,它将重新排列文本文件中的行,以便按数字和字母顺序对它们进行排序。 默认情况下,排序规则为:
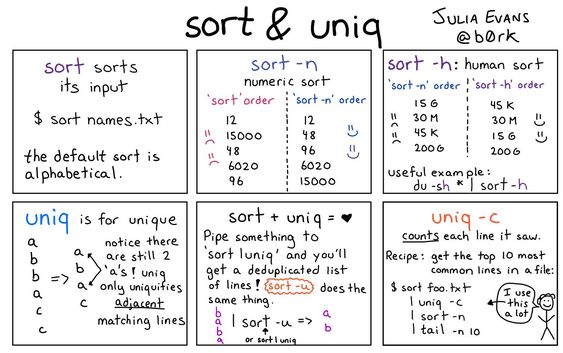
sort & uniq 命令卡通详解图
- 以数字开头的行,将出现在以字母开头的行之前。
- 排在字母表前面的字母的行,将出现在排在字母表后字母行的之前。
- 以小写字母开头的行,将出现在以大写字母开头的行之前。
sort 命令语法:
sort [OPTION]... [FILE]... sort [OPTION]... --files0-from=F
sort 命令选项:
#sort 排序选项: -b, --ignore-leading-blanks 忽略开头的空白。 -d, --dictionary-order 仅考虑空白、字母、数字。 -f, --ignore-case 将小写字母作为大写字母考虑。 -g, --general-numeric-sort 根据数字排序。 -i, --ignore-nonprinting 排除不可打印字符。 -M, --month-sort 按照非月份、一月、十二月的顺序排序。 -h, --human-numeric-sort 根据存储容量排序(注意使用大写字母,例如:2K 1G)。 -n, --numeric-sort 根据数字排序。 -R, --random-sort 随机排序,但分组相同的行。 --random-source=FILE 从FILE中获取随机长度的字节。 -r, --reverse 将结果倒序排列。 --sort=WORD 根据WORD排序,其中: general-numeric 等价于 -g,human-numeric 等价于 -h,month 等价于 -M,numeric 等价于 -n,random 等价于 -R,version 等价于 -V。 -V, --version-sort 文本中(版本)数字的自然排序。 #sort 其他选项: --batch-size=NMERGE 一次合并最多NMERGE个输入;超过部分使用临时文件。 -c, --check, --check=diagnose-first 检查输入是否已排序,该操作不会执行排序。 -C, --check=quiet, --check=silent 类似于 -c 选项,但不输出第一个未排序的行。 --compress-program=PROG 使用PROG压缩临时文件;使用PROG -d解压缩。 --debug 注释用于排序的行,发送可疑用法的警报到stderr。 --files0-from=F 从文件F中读取以NUL结尾的所有文件名称;如果F是 - ,那么从标准输入中读取名字。 -k, --key=KEYDEF 通过一个key排序;KEYDEF给出位置和类型。 -m, --merge 合并已排序文件,之后不再排序。 -o, --output=FILE 将结果写入FILE而不是标准输出。 -s, --stable 通过禁用最后的比较来稳定排序。 -S, --buffer-size=SIZE 使用SIZE作为内存缓存大小。 -t, --field-separator=SEP 使用SEP作为列的分隔符。 -T, --temporary-directory=DIR 使用DIR作为临时目录,而不是 $TMPDIR 或 /tmp;多次使用该选项指定多个临时目录。 --parallel=N 将并发运行的排序数更改为N。 -u, --unique 同时使用-c,严格检查排序;不同时使用-c,输出排序后去重的结果。 -z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。 --help 显示帮助信息并退出。 --version 显示版本信息并退出。 KEYDEF 的格式为:F[.C][OPTS][,F[.C][OPTS]] ,表示开始到结束的位置。 F 表示列的编号 C 表示 OPTS 为[bdfgiMhnRrV]中的一到多个字符,用于覆盖当前排序选项。 使用 --debug 选项可诊断出错误的用法。 SIZE 可以有以下的乘法后缀: % 内存的1%; b 1; K 1024(默认); 剩余的 M, G, T, P, E, Z, Y 可以类推出来。
sort 命令参数:
FILE(可选):要处理的文件,可以为任意数量。
sort 命令返回值:
返回 0 表示成功,返回 非0 值表示失败。
sort 命令实例
假设有 data.txt 文件,内容如下:
apples oranges pears kiwis bananas
sort 要按字母顺序对该文件中的行进行排序,请使用以下 sort 命令:
$ sort data.txt apples bananas kiwis oranges pears
您还可以使用内置的排序选项 -o,该选项允许您指定输出文件:
sort -o output.txt data.txt 等同于 sort data.txt > output.txt
您可以使用 -r 来让 sort 执行逆序排序。 例如,以下 sort 命令,忽略相同行使用 -u 选项或者 uniq:
$ sort -r data.txt pears oranges kiwis bananas apples
sort 处理混合数据
但是 sort 在行首混用大小写字母的情况下呢? 在这种情况下,排序的行为似乎令人困惑,但是实际上,sort 只需要您提供一些更多信息,即可按所需的方式对数据进行排序。 让我们仔细看看。这次假设我们的输入文件 data.txt 包含以下数据:
a b A B b c D d C 无需任何选择即可对数据进行排序,如下所示: $ sort data.txt a A b b B c C d D
如您所见,sort 是按字母顺序排序的,小写字母总是出现在大写字母之前。这种排序是“不区分大小写的”,这是 GNU 排序的默认值,GNU 排序是 GNU/Linux 中使用的排序的版本。
此时,您可能会问自己,如果不区分大小写的排序是默认的,那么 -f/-ignore-case 选项的作用是什么?答案:与本地化设置和按字节排序有关。
简而言之,“本地化”是指操作系统使用的语言,在最基本的级别上它定义了它使用的字符。系统中的每个字母均以一定顺序表示。更改语言环境设置将影响操作系统使用的字符,以及与排序最相关的字符的编码顺序。例如,请参阅美国英语 ASCII 编码表。
从表中可以看到,大写字母 A 是字符数字 65,小写字母 a 是字符数字 97。因此,您可能希望对 sort 进行排序,以便大写字母位于小写字母之前字母。
定义操作系统的语言环境是本文档讨论范围之外的主题,但是就目前而言,足以实现按字节排序,我们需要将环境变量LC_ALL设置为C。
在默认的 Linux shell bash 下,我们可以使用以下命令完成此操作:
export LC_ALL=C #这会将环境变量 LC_ALL 设置为值 C, #这将强制执行按字节排序。 现在,如果我们运行命令: $ sort data.txt A B C D a b b c d ...现在, 使用 -f/--ignore-case 选项,则结果为: A a B b b C c D d
sort 仅比较选定的数据字段
通常,sort决定如何基于整行对行进行排序:它将行中的第一个字符与最后一个字符进行比较。另一方面,如果要排序以比较数据的有限子集,则可以使用-k选项指定要比较的字段。这次包含以下数据的输入文件 data.txt:
01 Joe 02 Marie 03 Albert 04 Dave 执行 sort data.txt 输出: 01 Joe 02 Marie 03 Albert 04 Dave
由于行首的数字已被排序,因此原始数据的排序没有任何变化。但是,如果要基于名称进行排序,则可以使用以下命令 -k, --key=POS1[,POS2]在 POS1(起源1)处开始一个密钥,在 POS2(行的默认末尾)处结束:
$ sort -k 2,2 data.txt #此命令将对第二个字段进行排序,而忽略第一个字段。 #(“-k” 中的 “k” 代表 “key” - 我们正在定义比较中使用的“sorting key”) 字段定义为用空格隔开的任何东西; 在这种情况下,是实际的空格字符。上面的命令将产生以下输出: 03 Albert 04 Dave 01 Joe 02 Marie
sort 命令的坑:
如果将 join 命令与 sort 结合使用,请注意两个程序之间存在已知的不兼容性-除非您定义语言环境。如果使用联接和排序来处理相同的输入,则强烈建议将 LC_ALL 设置为 C,这将标准化所有程序使用的本地化。
sort 命令扩展阅读:
CommandNotFound ⚡️ 坑否 - 其他频道扩展阅读:
sort 命令评论
-
7zr 命令
aapt 命令
ack 命令
ar 命令
arj 命令
awk 命令
base32 命令
base64 命令
basename 命令
blkid 命令
blockdev 命令
bunzip2 命令
bzcat 命令
bzcmp 命令
bzdiff 命令
bzgrep 命令
bzip2 命令
bzip2recover 命令
bzless 命令
bzmore 命令
chattr 命令
chcon 命令
cksum 命令
cmp 命令
col 命令
colrm 命令
comm 命令
compress 命令
cp 命令
csplit 命令
csvstat 命令
cut 命令
dd 命令
diff 命令
diff3 命令
dircolors 命令
dirname 命令
dirs 命令
dump 命令
ed 命令
edit 命令
egrep 命令
enca 命令
ex 命令
extundelete 命令
file 命令
fmt 命令
fold 命令
fsck 命令
getfattr 命令
gettext 命令
grep 命令
gron 命令
gzip 命令
head 命令
join 命令
jq 命令
less 命令
link 命令
ln 命令
ls 命令
lsattr 命令
md5sum 命令
mkdir 命令
mmv 命令
more 命令
most 命令
msgfmt 命令
msginit 命令
mv 命令
namei 命令
nano 命令
nl 命令
nvim 命令
od 命令
paste 命令
pax 命令
rdfind 命令
rename 命令
rm 命令
rmdir 命令
sed 命令
setfattr 命令
sha224sum 命令
sha256sum 命令
sha384sum 命令
sha512sum 命令
shred 命令
sort 命令
srm 命令
stat 命令
strings 命令
sum 命令
tail 命令
tailf 命令
tar 命令
tee 命令
touch 命令
tr 命令
trash 命令
unarj 命令
uniq 命令
unlink 命令
unzip 命令
vi 命令
view 命令
vim 命令
vsftpd 命令
wc 命令
xargs 命令
xgettext 命令
zcat 命令
zip 命令
zipinfo 命令
zipsplit 命令
znew 命令
zstd 命令